Community articles — Algorithm
Recent

Maximization of muffler performance is important, but there is always space volume constraints. Shape optimization of multi-segments Muffler coupled with the GA searching technique. Outline: Problem Statement Derivation of Four Pole Matrices and an expression for STL Introduction to GA and it's Implementation A numerical case of noise elimination on pure tone Results and Discussion
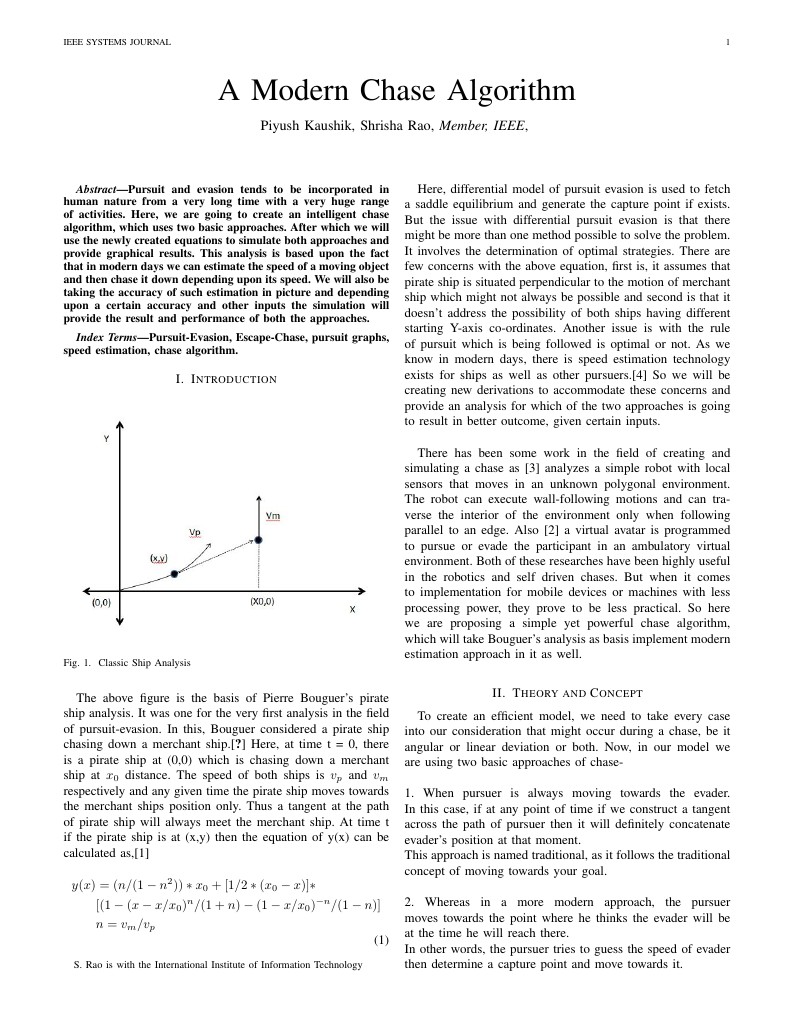
Pursuit and evasion tends to be incorporated in human nature from a very long time with a very huge range of activities. Here, we are going to create an intelligent chase algorithm, which uses two basic approaches. After which we will use the newly created equations to simulate both approaches and provide graphical results. This analysis is based upon the fact that in modern days we can estimate the speed of a moving object and then chase it down depending upon its speed. We will also be taking the accuracy of such estimation in picture and depending upon a certain accuracy and other inputs the simulation will provide the result and performance of both the approaches.

#algorithm #russian #homework

We are given spans of the target text which align to concepts in the AMR graph.These alignment do not cover every token in the target sentnce. Typically function words are not aligned to any graph fragment. Next, we obtain word alignments between the target sentence and source sentence. Since we have word alignments between target and source, and phrase alignments between target and AMR graph, we must convert the word alingments into phrase alignments. The phrases on the source side will then be projected to the AMR concepts via the target sentence

Testing is both technically and economically an important part of high quality software production. It has been estimated that testing accounts for half of the expenses in software production. Much of the testing is done manually or using other labor-intensive methods. It is thus vital for the software industry to develop efficient, cost effective, and automatic means and tools for software testing. Researchers have proposed several methods over years to generate automatically solution which have different drawbacks. This study examines automatic software testing optimization by using genetic algorithm approaches. This study will cover two approaches: a) obtain the sequence of regression tests that cover the greatest amount of code and b) once it is achieved another genetic algorithm will eliminate tests cases that cover the same section of code on the basis of still get the maximum code coverage. The overall aim of this research is to reduce the number of test cases that need to be run with the greatest amount of code covered.

In this paper we discuss how to price American, European and Asian options using a geometric Brownian motion model for stock price. We investigate the analytic solution for Black-Scholes differential equation for European options and consider numerical methods for approximating the price of other types of options. These numerical methods include Monte Carlo, binomial trees, trinomial trees and finite difference methods. We conclude our discussion with an investigation of how these methods perform with respect to the changes in different Greeks. Further analysing how the value of a certain Greeks affect the price of a given option.

Explain how the Floyd's cycle detection algorithm works.

This paper implements Simultaneous Localization and Mapping (SLAM) technique to construct a map of a given environment. A Real Time Appearance Based Mapping (RTAB-Map) approach was taken for accomplishing this task. Initially, a 2d occupancy grid and 3d octomap was created from a provided simulated environment. Next, a personal simulated environment was created for mapping as well. In this appearance based method, a process called Loop Closure is used to determine whether a robot has seen a location before or not. In this paper, it is seen that RTAB-Map is optimized for large scale and long term SLAM by using multiple strategies to allow for loop closure to be done in real time and the results depict that it can be an excellent solution for SLAM to develop robots that can map an environment in both 2d and 3d.

An indoor positioning system relying on time difference of arrival measurements of ultrasonic pings from fixed transmitters. Code available at https://github.com/YingVictor/ultrasonic-positioning
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.